
CountVectorizer là gì?
- ★
- ★
- ★
- ★
- ★
CountVectorizer là một công cụ tuyệt vời được cung cấp bởi thư viện scikit-learning bằng Python. Nó được sử dụng để chuyển một văn bản nhất định thành một vectơ trên cơ sở tần suất (số lượng (count)) của mỗi từ xuất hiện trong toàn bộ văn bản. Điều này rất hữu ích khi chúng ta có nhiều văn bản như vậy và chúng ta muốn chuyển đổi từng từ trong mỗi văn bản thành vectơ (để sử dụng trong phân tích văn bản sâu hơn).
Ví dụ xem xét một vài văn bản mẫu từ một tài liệu (mỗi văn bản là một phần tử danh sách):
document = [ “One Geek helps Two Geeks”, “Two Geeks help Four Geeks”, “Each Geek helps many other Geeks at GeeksforGeeks.”]
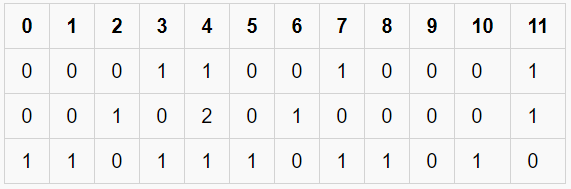
CountVectorizer tạo một ma trận (matrix) trong đó mỗi từ duy nhất được biểu thị bằng một cột (column) của ma trận và mỗi mẫu văn bản từ tài liệu là một hàng (row) trong ma trận. Giá trị của mỗi ô (cell) là số lượng từ trong mẫu văn bản cụ thể đó. Ví dụ như hình bên dưới:

- Có 12 từ duy nhất trong tài liệu, được biểu diễn dưới dạng các cột của bảng.
- Có 3 mẫu văn bản trong tài liệu, mỗi mẫu được biểu thị dưới dạng các hàng của bảng.
- Mỗi ô chứa một số, đại diện cho số lượng từ trong văn bản cụ thể đó.
- Tất cả các từ đã được chuyển đổi thành chữ thường.
- Các từ trong các cột đã được sắp xếp theo thứ tự bảng chữ cái.
Bên trong CountVectorizer, những từ này không được lưu trữ dưới dạng chuỗi. Thay vào đó, chúng được cung cấp một giá trị chỉ số (index) cụ thể. Trong trường hợp này, "at" sẽ có chỉ số 0, "each" sẽ có chỉ số 1, "four" sẽ có chỉ số 2, v.v. Biểu diễn thực tế đã được hiển thị trong bảng dưới đây.
Cách biểu diễn này được gọi là ma trận thưa (sparse matrix).
Bên dưới là code triển khai CountVectorizer trong Python.
from sklearn.feature_extraction.text import CountVectorizer
document = ["One Geek helps Two Geeks",
"Two Geeks help Four Geeks",
"Each Geek helps many other Geeks at GeeksforGeeks"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
vectorizer.fit(document)
# Printing the identified Unique words along with their indices
print("Vocabulary: ", vectorizer.vocabulary_)
# Encode the Document
vector = vectorizer.transform(document)
# Summarizing the Encoded Texts
print("Encoded Document is:")
print(vector.toarray())
Output:
Vocabulary: {'one': 9, 'geek': 3, 'helps': 7, 'two': 11, 'geeks': 4, 'help': 6, 'four': 2, 'each': 1, 'many': 8, 'other': 10, 'at': 0, 'geeksforgeeks': 5}
Encoded Document is:
[ [0 0 0 1 1 0 0 1 0 1 0 1]
[0 0 1 0 2 0 1 0 0 0 0 1]
[1 1 0 1 1 1 0 1 1 0 1 0] ]
Learning English Everyday